Textdatabas erbjuder nya sätt att studera andraspråksinlärning
Den 26 augusti lanseras en ny digital textsamling där Språkbanken Text vid Göteborgs universitet tillgängliggör cirka 1000 studentuppsatser. Uppsatserna är skrivna av studenter med ett annat modersmål än svenska och samlingen gör det möjligt att studera andraspråksutveckling på nya och enklare sätt.
Textsamlingen, den så kallade korpusen, har sammanställts i projektet SweLL – Swedish Learner Language som har engagerat forskare från universiteten i Göteborg, Stockholm, Umeå och Uppsala. Elena Volodina, forskare i Språkteknologi på Språkbanken Text vid Göteborgs universitet, har lett arbetet:
– Det har varit ett omfattande arbete att bygga korpusen och infrastrukturen för den manuella annoteringen, och vi har gjort långt mer än vad vi planerade. Nu ser jag fram emot att samlingen blir offentlig och kommer till användning!
Stöd för forskning inom svenska som andraspråk
Det finns flera liknande korpusar inom andra språk, men de är en bristvara i svenskan och svenska som andraspråk.
Materialet består av cirka 1000 uppsatser skrivna av vuxna som lär sig svenska. Insamlingen har skett i samarbete med flera skolor och arbetet med att digitalisera och annotera materialet har genomförts tillsammans med en mängd assistenter – något som varit tidskrävande arbete.
– Uppsatser produceras ju inte i samma takt som mycket annan skriven text. Dessutom har vi försökt balansera vår data så att den blir demografiskt och kunskapsmässigt representativ. Sedan kom ju pandemin på det. Det har inte varit det lättaste, säger Elena.
Synliggör språkliga fel på nya sätt
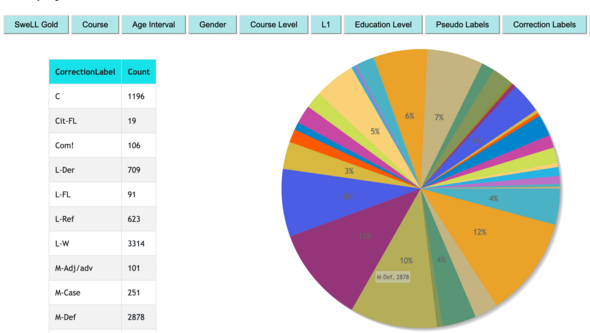
I projektet har man tagit fram en portal för att strukturera data och ett verktyg för annotering, normalisering och korr-annotering. Ett resultat av detta är ett nytt och tydligare sätt att presentera de språkliga fel som studenterna gör och intresset är redan stort.
– Andraspråksforskare ifrån bland annat Slovenien och Belgien, har redan visat intresse för verktyget och det känns såklart jätteroligt!
Utöver detta har projektet tagit fram grunder för hur man automatiskt kan anonymisera inlärardata.
– Det finns redan utarbetade sätt att göra detta på exempelvis medicinska data, men på den här typen av data har det fram till nu inte funnits något vedertaget arbetssätt – det har vi lagt grunden till.
Textsamling kan ge svar på viktiga språkfrågor
Användningsområdena för materialet är många. Genom analyser kommer man dels kunna ta reda på svaret på specifika frågor, till exempel hur en viss typ av andraspråkstalare lär sig bestämd form, eller på bredare frågor om hur förstaspråket påverkar att man lyckas eller inte lyckas i sitt lärande.
– Man skulle också kunna använda textsamlingen för att bedöma nivån på en skribent och i samband med detta kan man ta reda på vad personen behöver lära sig mer av för att komma vidare.
Lanseras i slutet av augusti
Den 26–27 augusti lanseras den nya resursen under ett onlineevenemang som är fördelat över två halvdagar. Vid lanseringen får du en presentation av textsamlingen, hur materialet har bearbetats och hur de nya verktygen kan användas.
Läs mer om projektet på projektsidan och anmäl dig till lanseringen på registreringslänken på evenemangssidan.
SweLL – Swedish Learner Language är ett samarbete mellan Göteborgs universitet, Stockholms universitet, Umeå universitet och Uppsala universitet. Projektet är finansierat av Riksbankens Jubileumsfond.
Fakta om uppsatser som tillgängliggörs via den första versionen av infrastrukturen:
- 502 uppsatser i SweLL-pilot korpusen som transkriberats och anonymiserats under 2007–2016
- 502 uppsatser i SweLL-gold korpusen som har transkriberats, pseudonymiserats, normaliserats och korr-annotaterats under 2017–2020