
”Mormor Karl” ska göra personuppgifter anonyma
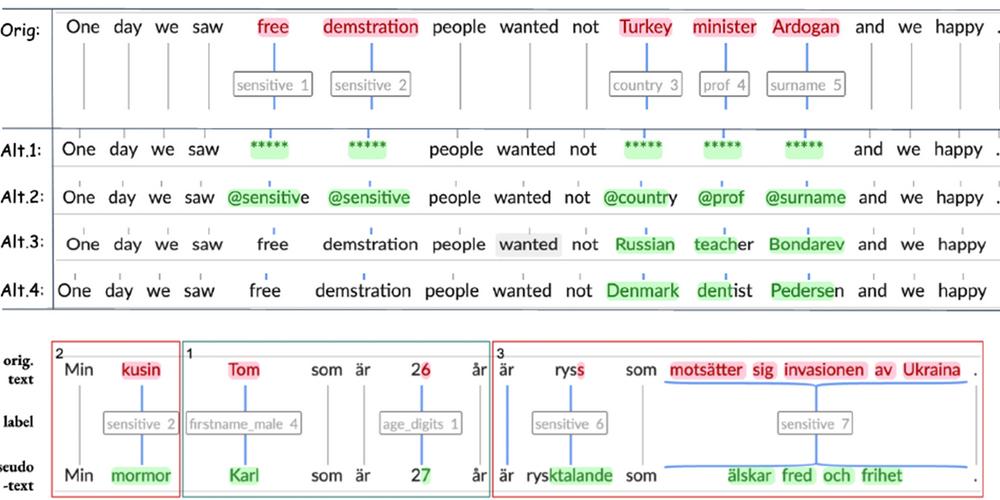
Texter som används som forskningsdata får inte innehålla personuppgifter som kan avslöja riktiga personer, något som i dag ofta hindrar forskare från att fritt använda textmaterialet. Forskningsmiljön ”Mormor Karl är 27 år” har getts nästan 18 miljoner kronor i bidrag från Vetenskapsrådet för att utveckla språkteknologiska algoritmer som automatiskt byter personuppgifter till en pseudonym i texter.

- I dag finns det risk att personer som nämns i ord i olika textmassor går att identifiera. Det kan vara med namn eller yrke, men också annan känslig information som politiska åsikter, berättar Elena Volodina, forskare vid Språkbanken Text vid Institutionen för svenska, flerspråkighet och språkteknologi.
Elena Volodina är huvudsökande till Vetenskapsrådet för forskningsmiljön Mormor Karl är 27 år: automatisk pseudonymisering av forskningsdata som i november getts 17,6 miljoner kronor i bidrag. Under de sex kommande åren ska gruppen systematiskt studera pseudonymer i större textmassor. Målet är att skapa språkteknologiska algoritmer som kan upptäcka personuppgifter och känslig information i stora textmassor och automatiskt ersätta orden med lämpliga pseudonymer. På så sätt kan personuppgifter skyddas och alla texter användas i olika slags forskning.
Algoritmer ska upptäcka personuppgifter automatiskt
Mormor Karl är 27 år samlar forskare från tre vetenskapliga discipliner: språkteknologi, datavetenskap och dataintegritet, samt lingvistik och språkinlärning. Tre nordiska universitet är engagerade i forskningsmiljön: Göteborgs universitet, Umeå universitet och Helsingfors universitet.
Forskarna i Mormor Karl är 27 år ska inledningsvis ringa in olika typer av identifikationer, alltså vad i texten som avgör om det är en personuppgift eller inte. Därefter kan de skapa språkteknologiska algoritmer som söker efter dessa identifikationer och ordet kan automatiskt bytas ut till ett annat.
Flera utmaningar ska lösas
För att kunna utveckla språkteknologiska algoritmer som upptäcker, markerar och ersätter personuppgifter behöver forskargruppen lösa olika utmaningar. Till exempel hur stavfel och flertydiga ord automatiskt ska upptäckas, men också säkerställa att texten som helhet stämmer överens med kontexten.
- Vi kommer också att analysera hur den här pseudonymiseringen påverkar texterna för andra forskare som i nästa led ska använda dem i sin egen forskning, säger Elena Volodina. Det kan vara att undersöka hur läsbarheten förändras när personuppgifter byts ut, eller vilket forskningsvärde de anonymiserade texterna kan ha för studier av till exempel språkinlärning.
Verktyget ska göras öppet och tillgängligt
Till en början utgår forskarna i Mormor Karl är 27 år från fritt skrivna texter, som studentuppsatser och sociala medier. När metoderna och de språkteknologiska algoritmerna är testade och med säkerhet fungerar på olika typer av texter kommer verktyget att göras tillgängligt för användning.
- Med den här forskningsmiljösatsningen kan vi stödja svenskt arbete med öppen tillgång till forskningsdata, säger Elena Volodina.
Text: Karin Wenzelberg
- Elena Volodina, Institutionen för svenska, flerspråkighet och språkteknologi, Göteborgs universitet
- Simon Dobnik, Institutionen för filosofi, lingvistik och vetenskapsteori, Göteborgs universitet
- Xuan-Son Vu, Institutionen för datavetenskap, Umeå universitet
- Therese Lindström Tiedemann, Department of Finnish, Finnougrian and Scandinavian studies, Helsingfors universitet
- Två doktorander - en vid Göteborgs universitet och en vid Helsingfors universitet

