
ATLASS
Short description
The overall aim of the project "ATLASS - Automated Transcription and Linkage of Archival School Data from Sweden" is to apply advances in machine learning and record linkage techniques to the detailed and structured information available in Swedish archives to build a unique research infrastructure with individual-level data on historical school records from the first half of the 20th century.
The core of the project is a historical source which harbours great potential for research in social sciences and humanities. Swedish municipal archives hold annual school records, Dagbok med Examenskatalog (‘Diary with Exam Catalogue’; DmE henceforth), listing all elementary school pupils' attendance and performance in every school year -- throughout the six or seven years of compulsory schooling. The project will digitise these historical school records to generate a database of 2.4 million individual observations originating from 1,200 school districts -- which represents the majority of school districts and the majority of pupils born between 1905 and 1941. What makes this source, and the resulting database, unique also in an international perspective is the richness and the completeness of the information combined with the possibilities to link individuals to other data sources.

|

|

|

|

|
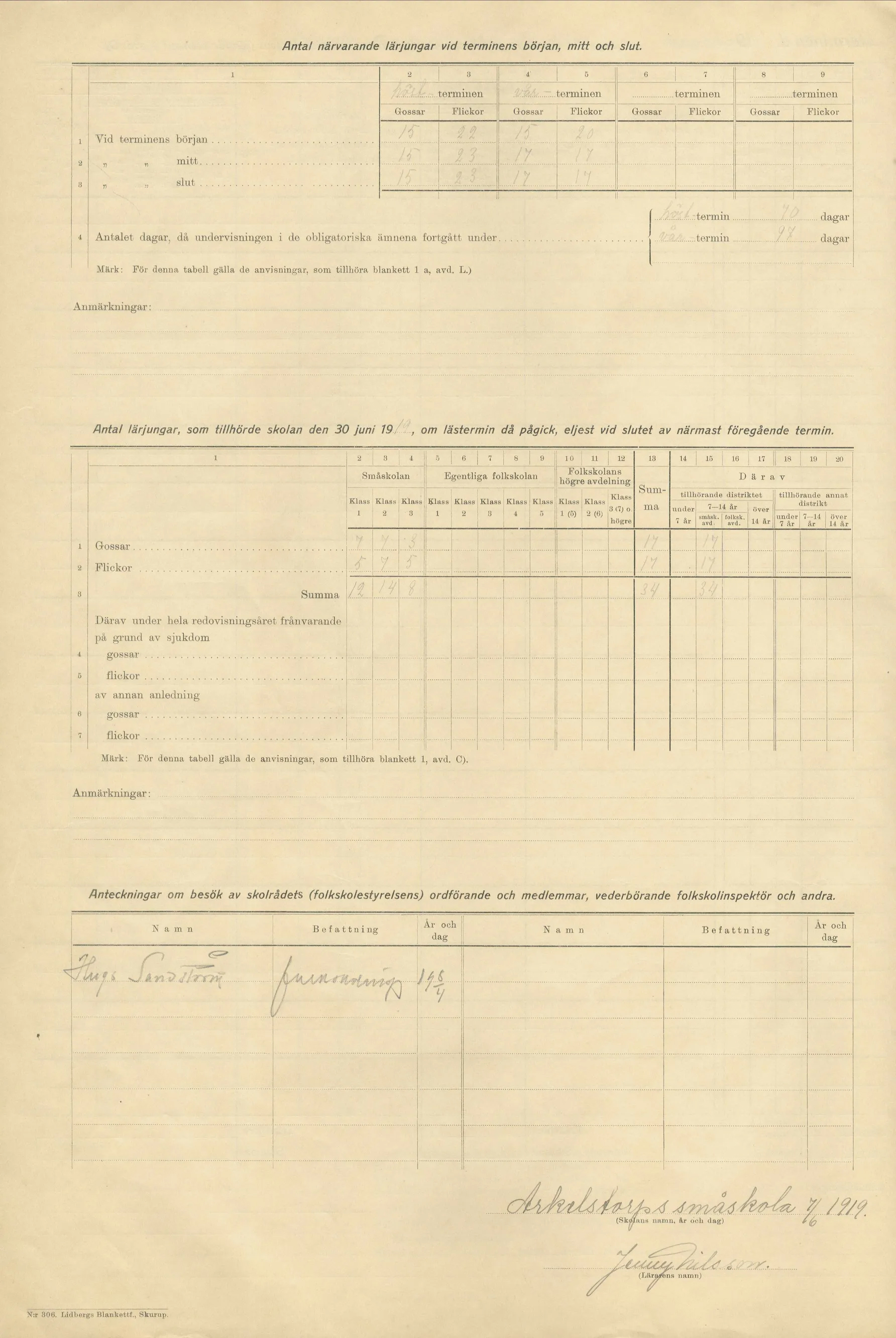
|
For virtually the universe of pupils, the data contains information on:
- School grades in individual subjects twice annually.
- Two behavioural grades.
- Presence and absence by cause of absence for each day of term.
- Name of teacher and class membership.
- Type of school and length of term.
- Grade retention and transition to secondary schooling.
Data Sources and Variables (click to enlarge)
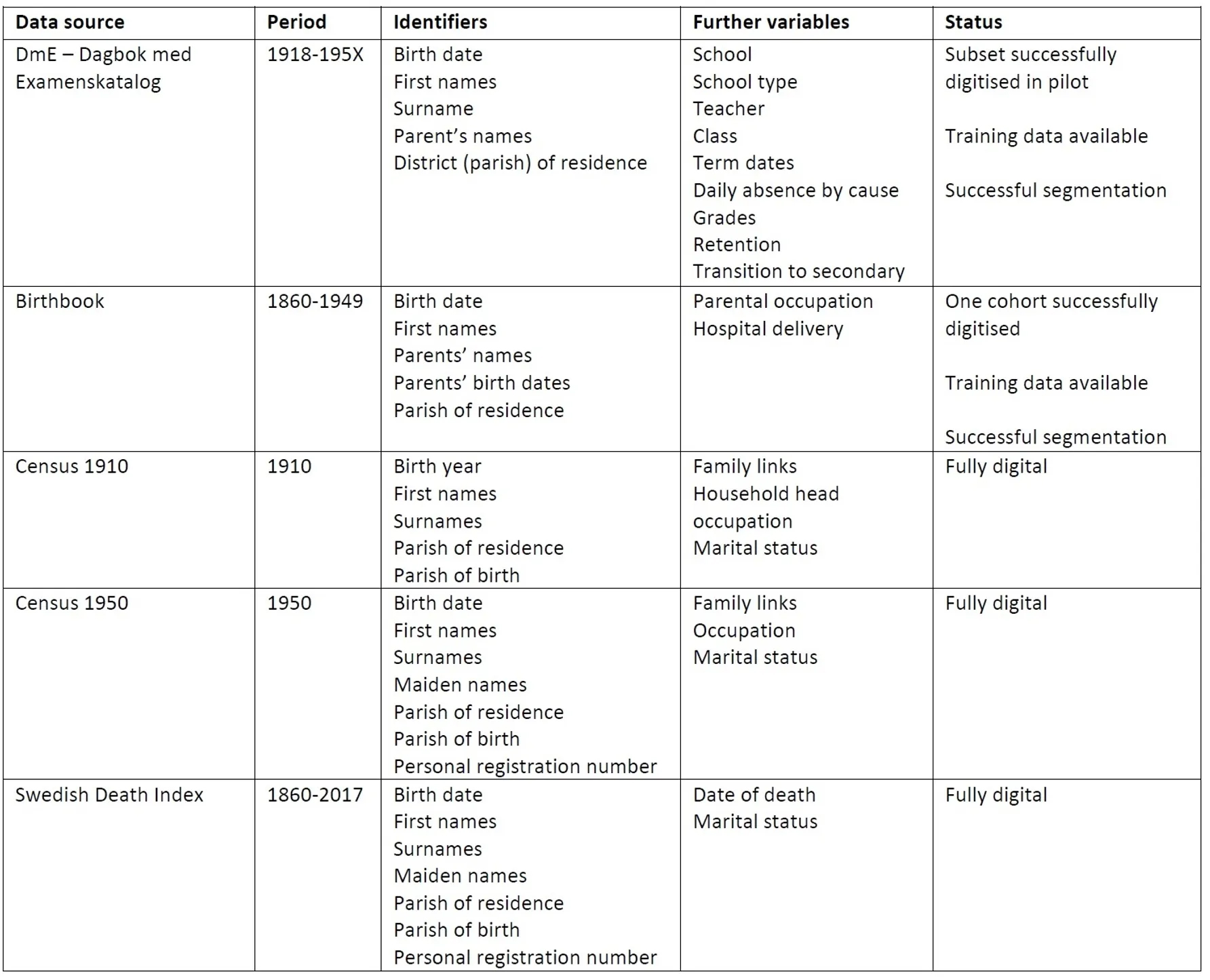
The Swedish context provides an opportunity to link these data to other sources, including historical censuses and modern registers. Based on information on forenames, surname, exact date and place of birth, almost all Swedes are unique. Therefore, the pupil records from the DmE can be linked forward in time to censuses and all modern administrative data available for the entire Swedish population. They can also, however, be linked back to their birth records -- leading to complete family links including parents, siblings, and other relatives.
Project Aims
The aims of the project are:
- To digitise all birth certificates for the cohorts 1900-49, including information on parents.
- To digitise complete school records (DmE) for 2.4 million pupils attending school during the 1918-49 period (i.e., cohorts born 1905-1941).
- To link the digitised records to the censuses 1910 and 1950, and to the Swedish Death Index.
- To clean and document the data, and harmonise coding schemes with existing research infrastructures.
The project is perfectly scalable. While the above aims are based on a digitisation of 7 academic years in five-year intervals between the 1918/19 and 1948/49, the infrastructure allows for future additions of academic years, pupils, and school districts.
Collaboration with Archives
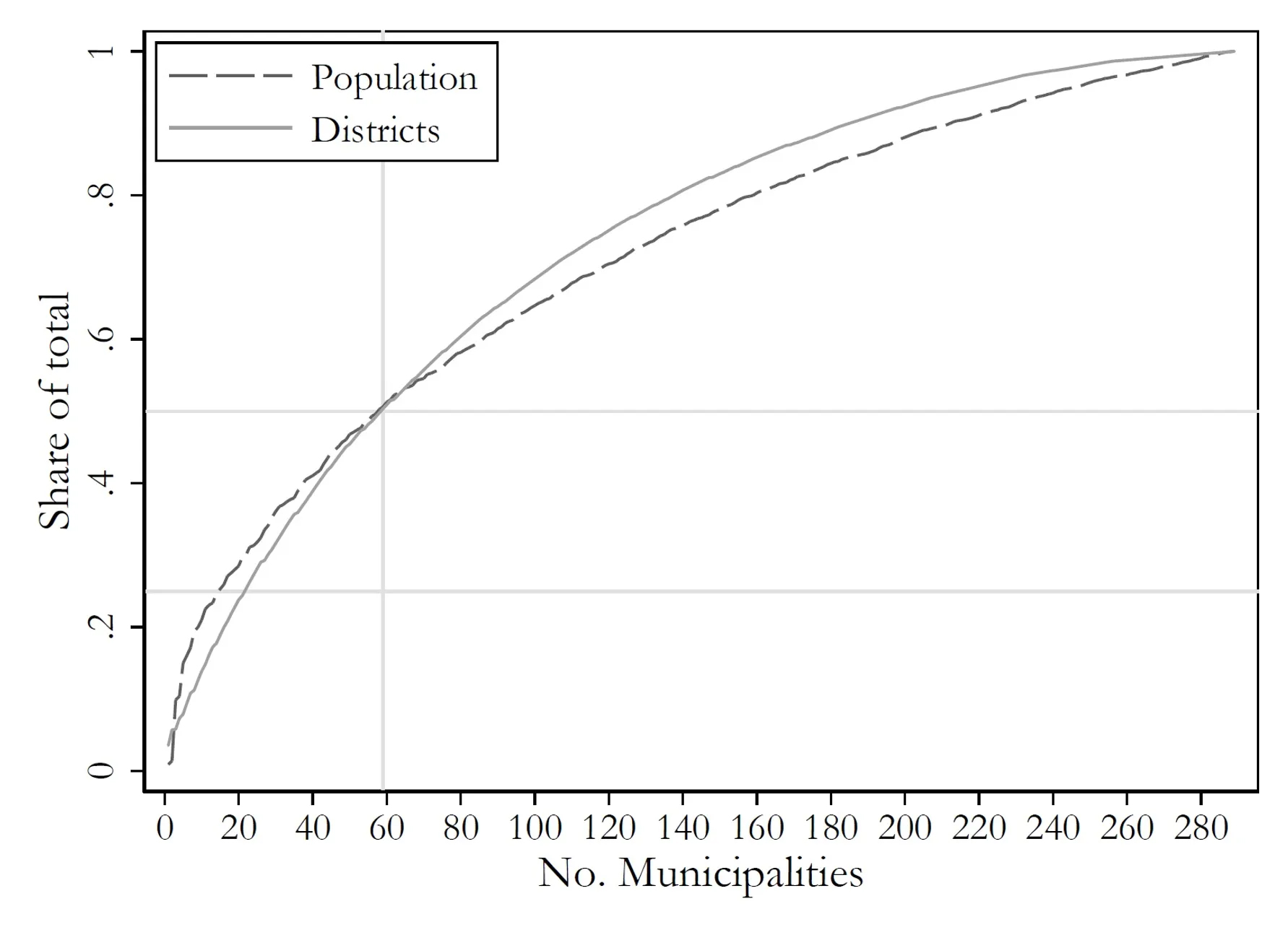
Although it would be desirable to include all 290 local archives in the project, it is not realistic that small and remote municipalities can be motivated to participate in the initial phases. However, what is important from the point of view of research is that the resulting dataset is large enough to reflect an interesting population. Thus, the project aims at covering at least half the pupil population and at least half of the 2,500 school districts that existed in the country.
In fact, only 59 of the 290 archives are necessary in order to include a majority of pupils and a majority of school districts - as the below figure shows.
Number of Municipal Archives Needed to Achieve Different Levels of Coverage (click to enlarge)
Amount of Data
During the 1918-49 period, the number of pupils attending elementary schooling in a year was relatively stable, averaging 662,000 and varying in the range 600,000-750,000 (cf. SCB, 1974). With an average of 25 pupils per class (see table below), this would imply there were 26,500 classes on average in a year. Based on data provided by the collaborating archives during the pilot, we estimate that one academic year corresponds to around 600,000 pages. Given the project's ambition of covering seven academic years for half of the country, the source data needed correspond to around 2,100,000 pages.
National Statistics on Pupils and Classes for the Academic Year 1926-27 (click to enlarge)
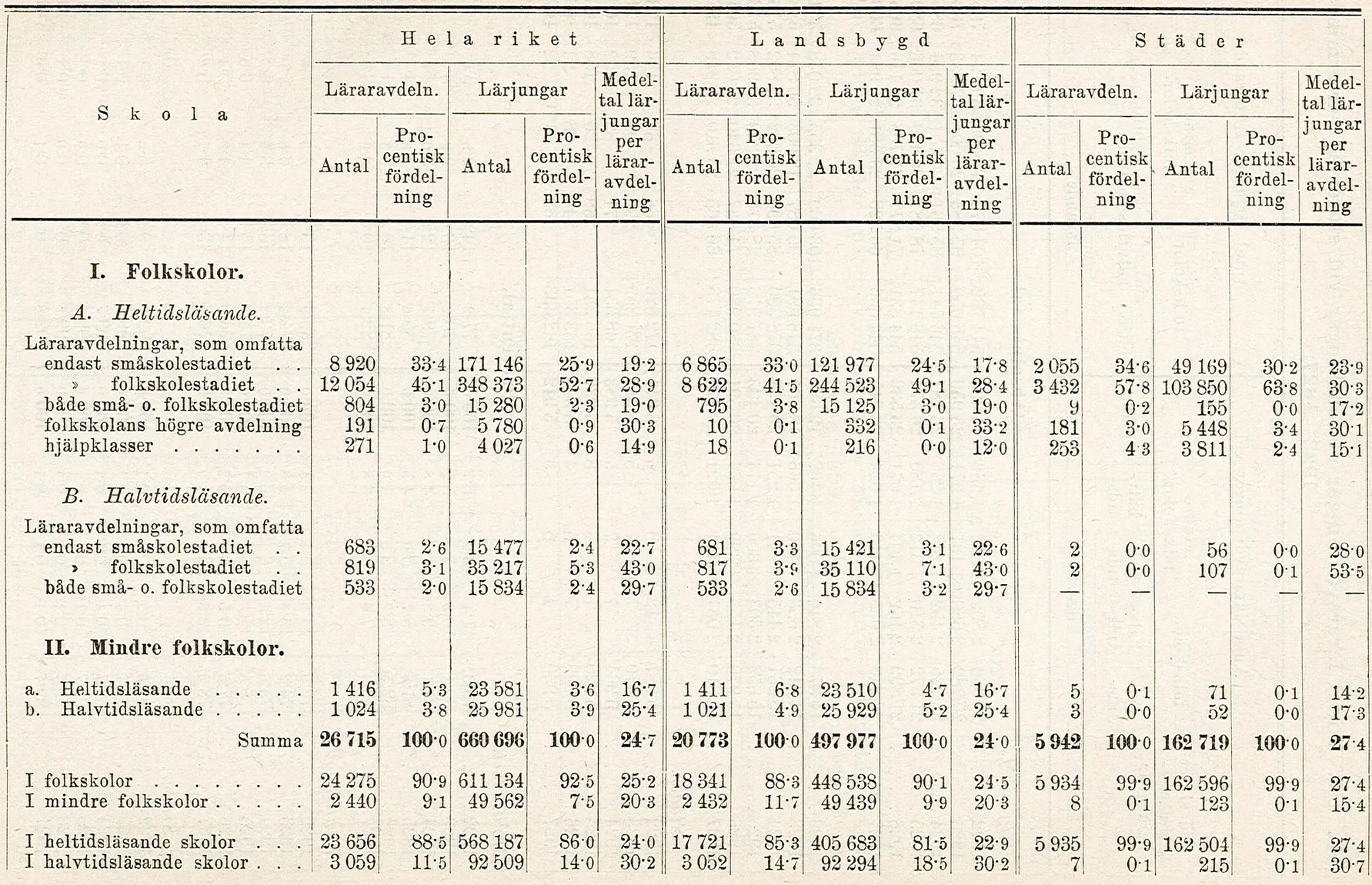
Source: SCB (1928).
Automated Transcription
The scanned images will be transcribed using machine learning methods and a fully automated transcription pipeline (cf. Dahl et al, 2021). We will transcribe all contents of the DmE:s -- i.e. all district-level, school-level, class-level and individual-level variables. This requires a large amount of training data.
'Transkribus' (Muehlberger et al, 2019) and 'Monk' (Schomaker, 2019) are existing methods that focus on transcription of historical manuscripts, mostly applied to streams of handwritten text. Technologies such as Transkribus and Monk are not specifically designed to transcribe tabular data and they require manual adaptations to work on complex tables, see, e.g., Muehlberger et al (2019). While there has been work to adapt Transkribus to table transcription, the current approaches are not fully automatic and they entail a significant manual workload related to segmentation and drawing of baselines. When the table complexity is high and the document count is large, even minor manual input per document will drastically increase the overall workload. In such cases, fully automated transcription is preferable, see, Dahl et al (2021).
Value for Research
The infrastructure caters to a pressing need of the research community. The period covered represents a transformative period for Swedish society, with changes affecting the education system, the labour market, social mobility, and the social safety net. Yet there is a notable lack of large databases covering the period 1910-50 compared to periods before and after. Any quantitatively oriented empirical research project interested in the societal transformations of this period, or their remaining impact today, would benefit from the infrastructure.
The primary source, DmE, has been used in previous projects relying on manual digitisation and substandard methods for record linkage (cf. Bhalotra et al, 2021, Fischer et al, 2021). Key differences between the current project and those previous digitisation initiatives are
- the size of the resulting dataset, which is several orders of magnitude larger;
- the systematic selection criteria, leading to coverage of a majority of pupils over an extended period;
- the scientific approach to transcription and linkage; and
- the scalability: possibility to add further cohorts and school districts.
Potential Research Programmes
Given the size of the resulting database, in terms of individuals and contents included, we expect it will enable a large number of diverse research projects. We now highlight some of the research areas that we imagine will benefit in particular.
-
Research taking a long-term view on the consequences of inequality within the school system. The period was marked by a number of reforms that in some cases increased (e.g. compulsory schooling extensions) and in some cases reduced (e.g. opening of secondary schools) the equality in educational attainment. The DmEs contain exact information on exposure to those reforms. They also include information relevant to understand the degree of inequality arising out of sorting of pupils and teachers. In combination, the data enable a comprehensive analysis of how the school system contributed to inequality of opportunity over an extended period (Abbott & Gallipoli, 2020).
-
Research seeking to understand the forces driving the rapid expansion in female labour force participation in the post-war area. Improved work opportunities for married women and increased state support for families coincided with changes in educational opportunities. The lack of schooling information and suitable longitudinal data for the pivotal cohorts have previously made it difficult to disentangle these mechanisms. The digitized data will facilitate understanding of the role of individual decisions – regarding e.g. skill formation, schooling, or childbearing, for women of different backgrounds (cf. Bhalotra et al, 2021).
-
Research seeking to understand mediating relationships for early-life environmental factors. A large literature in economics, epidemiology, and other disciplines trace adult health and socioeconomic outcomes back to the early life environment. Such studies typically fail to establish when and how the effects of such influences materialise, the variables relevant in the mediation, and how parents adjust their behaviour in response (cf. Conti et al, 2019; Berlinski & Vera-Hernandez, 2019). The cognitive and social skills recorded in the DmE represent key mechanisms for many such early-life influences and the infrastructure will have detailed information on parents and siblings.
-
Research studying the intergenerational transmission of socioeconomic status. Having a combination of school performance, adult outcomes, and family background for subsequent generations, will be helpful for expanding our knowledge on the intergenerational dynamics of advantage. This includes descriptive studies of social mobility over time, how it differed across demographic groups and across the distribution of outcomes, and how it was affected by educational reforms (cf. Song et al, 2020; Stuhler et al, 2018).

Martin Karlsson
Martin is full professor at the University of Duisburg-Essen, Director of CINCH, its national research centre for health economics, and an affiliated professor at the Department of Economics at the University of Gothenburg. Martin's research is mainly devoted to studying the consequences of the emergence of the welfare state during the first half of the 20th century. He has ample experience of working with all the datasets and historical sources considered in this project, and he is an established expert on the record linkage of historical data from Sweden.

Christian Møller Dahl
Christian is full professor at the University of Southern Denmark. Christian is heading the research group Big Data Analytics and Digitization at SDU specializing in developing machine learning methods for automated transcription of handwritten text from historical tabular documents (at a large scale).

Gustav Kjellsson
Gustav is associate professor at the University of Gothenburg. One strand of his research focus on socioeconomic inequality, and how education affects future outcomes. Gustav has vast experiences of handling large data set of sensitive information.

Mikael Lindahl
Mikael is full professor at the University of Gothenburg. His research is mainly in the areas of intergenerational mobility and economics of education. Among his most recent work involves the study of social mobility across several generations in Sweden. He has experience working with data sets from many different sources, including historical data, and on projects which included compiling data from archives.

Scientific Advisory Board
The project group works in close co-operation with a group of international scholars, who belong to the internationally most distinguished experts in the methods that are critical in the project. This group will form a scientific advisory board which supports the PIs in issues of strategic importance. It consists of:
-
Ran Abramitzky (Stanford University), who is a leading expert on the record linkage of historical data;
-
Sonia Bhalotra (Univesity of Warwick), who is a leading scholar in empirical research on early childhood development and health;
-
Kasey Buckles (Notre Dame University), with expertise in record linkage and in economic demography;
-
Dora Costa (UCLA), who is an expert on intergenerational transmission of health and socioeconomic status, with ample experience of working with historical data from a range of different countries.
National Archives
The Swedish National Archives is a governmental agency under the Ministry of Culture with the assignment to safeguard society’s archival information, and make it accessible for use over time.
The Swedish National Archives recognises the great value of the proposed research infrastructure ATLASS to the research community and to society at large. The scope and goal of the infrastructure aim to create an important link between demographical data and the societal effects of education, as well as furthering methodological research into uses of machine learning in handwritten archival materials. Therefore, National Archives is committed to support the infrastructure in a number of areas where their knowledge, experience and resources are conducive to the successful execution of the project.
In particular, they offer to assist the infrastructure in the following ways, if the infrastructure will get funded:
-
The Swedish National Archives offers to carry out scanning of source documents from municipal archives. This offer includes transportation of the documents from the municipal archives to the digitization facility. They offer to carry out the scanning at the standard going rate that has been offered to the infrastructure, plus the transportation cost. Their capacity suffices to carry out all the scanning required for the project within three years.
-
The Swedish National Archives has completed and has ongoing research projects concerning HTR and machine learning, working on material from the same time period as the proposed research infrastructure. Ongoing transfer of knowledge and experiences between the research group and the Swedish National Archives already take place, and will continue during the infrastructure’s funding period. The projects and infrastructures at the Swedish National Archives also produce training data that are relevant for the proposed infrastructure. These data will be made publically available via our data platform that is currently under development.
-
Within the research project SweCens and the research infrastructure SwedPop, of which the Swedish National Archives is part, consistent coding schemes have been developed for occupations and geographical units (such as e.g. parishes and municipalities). The National Archives would be happy to transfer this knowledge to the proposed research infrastructure, and to give advice on their appropriate implementation of the data at hand.
Lampyrine Studios
Lampyrine Studios is a web solution company based in Malmö, Sweden. It is responsible for the development of all the webapp software needed in the project.